Введение в метрики Apache Cassandra
Для чего нужны метрики
В этой статье опишу базовые понятия и расскажу как правильно читать метрики. В последующих статьях расскажу про некоторые конкретные метрики, на что они влияют и что может влиять на них.
Метрики - это численные показатели каких-либо свойств системы. Они являются очень полезным инструментом для обнаружения и локализации проблем, возникающих в процессе эксплуатации компьютерных систем. Отслеживание метрик должно быть обязательной частью мониторинга системы, иначе неизбежно появится необъяснимая неведомая “магия” в поведении системы. Кроме того, метрики крайне полезны при тестировании производительности и определении узких мест системы.
Apache Cassandra предоставляет большое количество метрик охватывающих все аспекты ее работы.
Инструменты для сбора метрик.
Apache Cassandra использует технологию JMX для доступа к системным свойствам и метрикам. Для того чтобы получить доступ к метрикам Сassandra подойдет любой инструмент поддерживающий эту технологию, в интернете есть множество информации на эту тему, я приведу лишь краткий список:
- Nodetool - стандартная консольная утилита для Apache Cassandra, подходит для быстрого просмотра показателей, но не умеет их собирать
- JConsole - стандартная java утилита с графическим интерфейсом, идет в комплекте с JDK
- mx4j - HTTP/HTML интерфейс для jmx
- DataStax OpsCenter - мощный инструмент для мониторинга, но платный
- Zabbix большой комбаин для продакшен мониторинга всего что угодно
- Какое-либо свое решение на основе библиотек для получения данных из jmx (например jmxtrans) и экспорта их в систему сбора и визуализации метрик (например Graphite)
Описание и интерпретация метрик
Для правильного понимания и интерпретации метрик нужно сказать пару слов о SEDA (Staged Event Driven Architecture) подходе, так как Кассандра реализует именно его.
SEDA предполагает поэтапную (Stage) асинхронную обработку событий (event), когда события группируются в Stages (так называемые этапы или ступени) каждый stage имеет свою очередь (queue) и пул потоков (thread pool) для обработки событий. Если нет свободного потока для обработки очередного события, то это событие будет ожидать обработки в очереди, пока не появится свободный поток. Если очередь наполняется быстрее, чем данные обрабатываются, то очередь в конце концов переполняется и вновь поступающие события блокируются или сбрасываются.
Таким образом, чтоб получить представление о потенциальных проблемах достаточно взглянуть на количество ожидающих задач в очереди (pending) и количество заблокированных (blocked) задач, например с помощью nodetool tpstats:

Та же информация через jConsole:
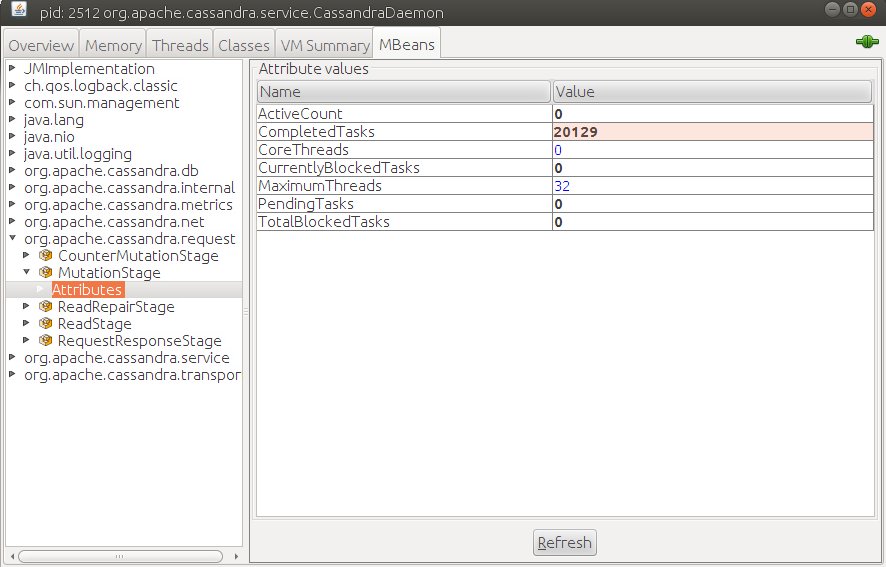
Всего есть 5 состояний задач:
- Active (ActiveCount) - количество задач в данный момент находящихся в обработке
- Completed (CompletedTasks) - количество всех выполненных задач
- Pending (PendingTasks) - количество задач находящихся в очереди на обработку в данный момент
- Blocked (CurrentlyBlockedTasks) - количество заблокированных задач, тех что не поместились в очередь в данный момент
- All time blocked (TotalBlockedTask) - количество всех заблокированных задач.
Эти состояния определяются работой потоков. Значение CoreThreads показывает минимальное количество потоков доступных для обработки задачи этого этапа. MaximumThreads показывает максимальное количество потоков доступных для обработки задач этого этапа. CoreThreads равно 0 если отсутствует какая либо нагрузка, и может увеличиваться до MaximumThreads, при перегрузке, когда достигается максимум PendingTasks и MaximumThreads новые поступающие задачи блокируются.
Ниже представлен список основных stages:
- MutationStage - операции записи данных
- ReadStage - операции чтения данных
- ReadRepairStage - операции механизма Read repair
- RequestResponseStage - различные операции обработки ответов
- AntiEntropyStage - операции восстановления согласованности данных между нодами с помощью административных инструментов (например nodetool repair)
- MemtableFlushWriter - операции сортировки и записи данных на диск из memtable
- MemtablePostFlusher - операции происходящие после записи memtable на диск (например сброс commitlog’а)
- MigrationStage - операции изменения схемы данных
- ComactionExecutor - оперции слияния и оптимизации данных на SSTable (Compaction механизм)
- HintedHandoff - операции восстановления согласованности данных для нод которые были недоступны какое-то время.
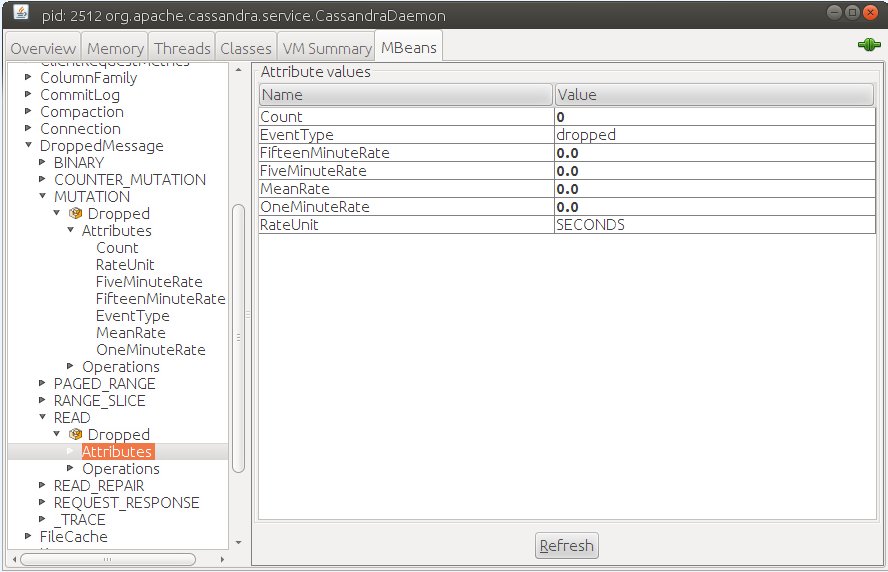
Как говорилось выше, если кассандра не в состоянии обработать какую-то задачу из-за чрезмерной нагрузки и выполнение этой задачи не является критичным, то такая задача сбрасывается после таймаута. Статистику по таким “брошенным” задачам можно увидеть по JMX пути: org.apache.cassandra.metrics:type=DroppedMessage с помощью jConsole или всё той же nodetool tpstats:
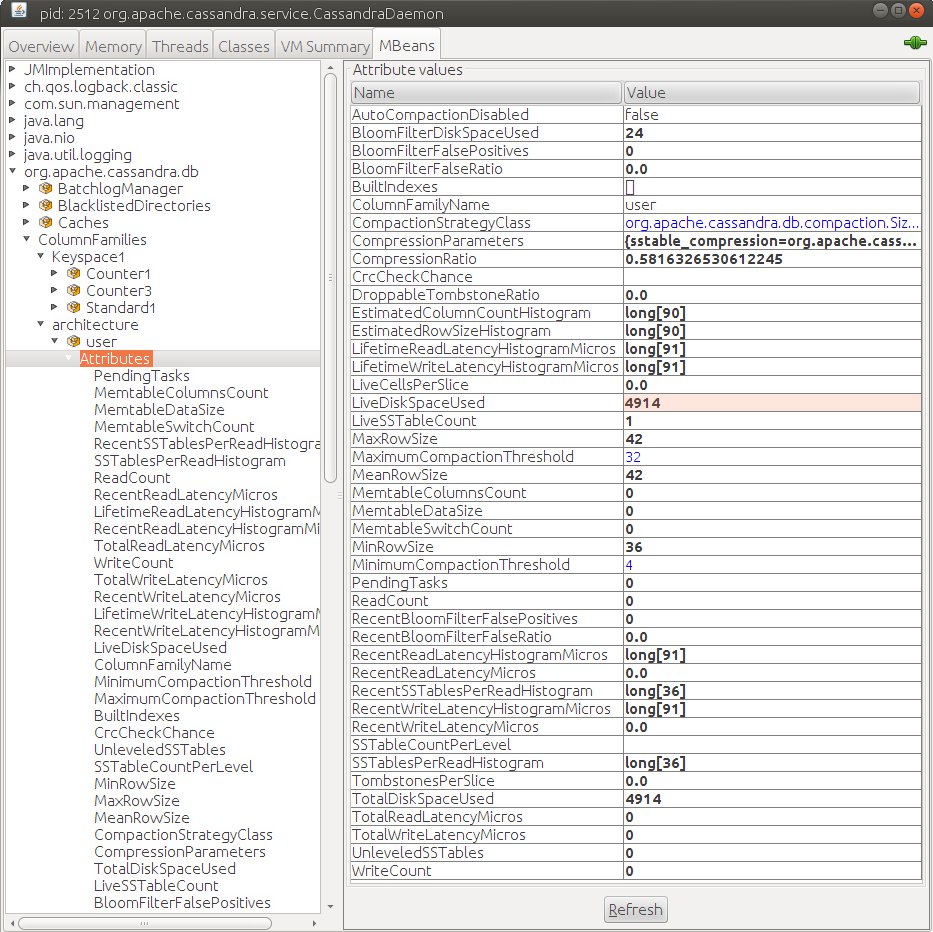
Для более глубокого анализа бывает полезно знать статистику конкретно по определенным семействам колонок. Каждое семейство колонок имеет набор метрик со значениями актуальными именно для него. Данные доступны по JMX пути org.apache.cassndra.db:type=ColumnFamilies
На этом с общим описанием метрик всё, в следующих статьях приведу подробные описания некоторых метрик, расскажу какой эффект оказывают те или иные значения метрик на поведение системы и о чем могут свидетельствовать нездоровые значения этих метрик.