Bucketing: разбиваем большие партиции с помощью согласованного хэширования
Слишком большие партиции
У Partition Key (ключ раздела) есть два основных аспекта:
- С точки зрения пользователя, этот ключ определяет как пользователь будет читать данные. Является основным параметром при создании модели данных.
- С точки зрения самой Apache Cassandra, определяет где физически будут находится данные в кластере, на каких узлах.
Оптимальным вариантом модели данных, с точки зрения скорости чтения, будет записать все, что нам нужно в одну партицию. Зная ключ этой партиции, мы за один запрос к базе получим все что нам нужно. Но что если таких данных очень много?
С точки зрения самой базы, данные по одному ключу всегда лежат на одном узле и не распределяются по кластеру, что приводит к проблемам с масштабированием и ограничениям на размер партиции:
- Разбалансировка кластера, один (или несколько узлов, в зависимости от replication factor) содержат весь объем записей, в то время как другие узлы пустуют. То есть шардирования никакого нет.
- Операции чтения и записи обрабатываются на части узлов, нагрузка при чтении и записи не распределяется равномерно на весь кластер.
- Tombstones. Если есть много операций удаления, то надгробия, как и данные не распределяются по кластеру, а копятся на определенных узлах.
- Ограничение в 2 миллиарда записей для одного partition key. Но рекомендуется не более “нескольких сотен тысяч” или “нескольких сотен мегабайт”.
Ставим лайки
Рассмотрим на примере. Есть веб-сайт, пользователи имеют возможность публиковать записи, и “лайкать” понравившиеся публикации. Для каждой публикации мы хотим иметь список пользователей “лайкнувших” эту публикацию. Для этих целей создадим таблицу:
CREATE TABLE likes_by_post (
post_id uuid,
user_id text,
user_first_name text,
user_last_name text,
time timestamp,
PRIMARY KEY ((post_id), user_id)С точки зрения Apache Cassandra она будет выглядеть так:

Зная id публикации мы можем получить всех пользователей, кто поставил лайк.
Наш веб-сайт становится очень популярным, пользователей становится все больше и больше, и вот уже всё населения мира зарегистрировано у нас на сайте. Часть публикаций нравится почти всем пользователям, что приводит к тому что эти статьи “лайкают” миллиарды пользователей, в итоге мы достигаем предела возможностей Кассандры хранить 2 миллиарда лайков для одной публикации.
Bucketing
Для того, чтобы решить проблему безграничных партиций используется подход называемый “бакетирование” (bucketing). Основная идея здесь в том, чтобы разбить все множество записей внутри одной партиции на более мелкие части (корзины или buckets). И эти корзины хранить как отдельные партиции в Apache Cassandra.
Существуют различные подходы и критерии, по которым данные раскладываются по корзинам:
- По интервалам времени, например, каждые сутки создается новая корзина, тогда ключём партиции будут id публикации и дата, и в этой партиции будут “лайки” только за определенную дату.
- По размеру корзины, когда количество записей в корзине фиксировано и если записей становится больше чем задано, то создается новая корзина. Например, задаем размер корзины в 100 тысяч лайков. Первые 100 тысяч лайков сохраняются в корзину с номером 0, вторые с номером 1 и так далее. Ключём партиции будут id публикации и номер корзины.
- По фиксированному количеству корзин. В этом случае у нас будет фиксированное число корзин и записи будут раскладываться по ним в соответствии с определенным алгоритмом, который на вход принимает сами данные, а на выходе дает номер корзины (из диапазона допустимых номеров). В случае с лайками алгоритму передается, например, id пользователя, который “лайкнул” публикацию, а на выходе получается число с номером корзины. Ключём партиции будут id публикации и номер корзины.
Про первые два подхода будут отдельные статьи, а сейчас рассмотрим 3 подход.
Bucketing + Consistency hashing
Преимущество данного подхода в его простоте, не нужно никаких дополнительных таблиц, для того чтобы знать в какую корзину записывать данные, сколько всего корзин и так далее. Недостаток в том, что количество корзин фиксировано, а вот количество записей в корзине - нет. Но если общее количество данных известно заранее, то можно подобрать максимальное количество корзин таким образом, чтобы размер самих корзин не был слишком большим. Еще один момент состоит в том, что количество корзин не должно быть очень большим, так как чтобы извлечь все данные, необходимо запросить все корзины, чем больше корзин - тем больше запросов к базе. Здесь нужно учитывать и объем данных, и количество узлов в кластере, и ожидаемую производительность.
Теперь перейдем к задаче вычисления номера корзины для заданного максимального числа корзин и собственно самих данных, которые хотим положить в корзину. Этот алгоритм широко применяется в распределенных системах, в том числе и в Apache Cassandra, и называется согласованное хэширование. Согласованное хэширование используется как раз для того, чтобы по ключу определить, на каком узле должны лежать данные. Останавливаться на описании этого алгоритма я не буду, в конце статьи есть ссылки на материалы по данной теме. Здесь же рассмотрим непосредственно пример использования и немного кода.
Раскладываем “лайки” в корзины
Для начала создадим таблицу likes_by_post_and_buckets:
CREATE TABLE likes_by_post_and_buckets (
post_id uuid,
bucket int
user_id text,
user_first_name text,
user_last_name text,
time timestamp,
PRIMARY KEY ((post_id, bucket), user_id))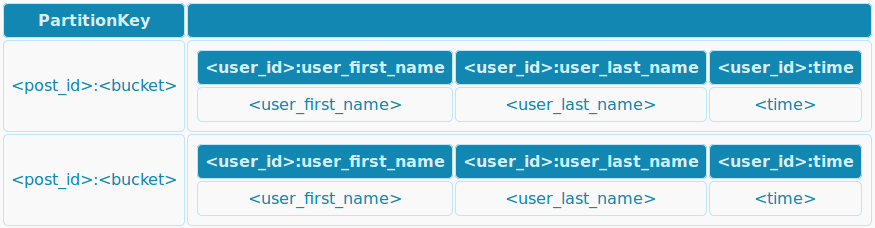
Здесь ключём партиции будут id публикации (поле post_id) и номер корзины (поле bucket).
Теперь нам нужно определиться с максимальным числом корзин. Как я уже писал выше, это число не должно быть очень большим, ведь мы не хотим выполнять тысячи запросов для того чтобы получить всех пользователей, кому понравилась публикация. С другой стороны, слишком большие корзины тоже не очень хорошо с точки зрения распределения данных по кластеру и горизонтального масштабирования. Представим, что у нас есть 7 миллиардов пользователей (или сколько сейчас население Земли?). Грубо говоря, мы можем 7 миллиардов разделить на 2 миллиарда (максимальный размер партиции), и получим, что нам нужно 4 корзины, с другой стороны, если есть кластер с сотней другой узлов, то 4 корзины не обеспечат хорошего распределения данных. Как другой вариант можно взять значение параметра num_tokens, который в Apache Cassandra как раз таки и участвует в распределении данных по узлам. По умолчанию это значение равно 256. Давайте его и используем для нашего примера. Но, повторюсь, в каждом конкретном случае нужно подумать о том какое значение выбирать.
Итак, начнем писать класс, который сохраняет и возвращает лайки для публикаций, зададим максимальное количество корзин:
public class LikesByPost {
static final int MAX_BUCKETS = 256;
}Теперь напишем код для сохранения “лайка”. Но перед сохранением в базу нужно определить номер корзины, в этом поможет библиотека Google Guava, а именно методы из класса Hashing. Добавим метод, который по идентификатору пользователя определяет номер корзины, в которую мы положим “лайк” этого пользователя.
public int getBucket(final String userId) {
HashCode hash = Hashing.murmur3_128().hashString(userId, Charsets.UTF_8);
return Hashing.consistentHash(hash, MAX_BUCKETS);
}Считаем хэш с помощью murmur функции. Эта функция достаточно быстрая и 128 битный вариант гарантированно не воспроизводит одинаковых значений для 64 разрядных процессоров. Здесь я взял только userId, потому что именно userId определяет уникальность лайка, то есть мы используем кластерный ключ из первой таблицы. И назначаем идентификатору пользователя корзину из нашего диапазона от 0 до 256.
Теперь используем метод getBucket в методе сохранения “лайка”:
public void like(final UUID postId, final User user) {
Session session = CassandraDriver.getSession();
int bucket = getBucket(user.getId());
session.execute("INSERT INTO likes_by_post_and_bucket (post_id, bucket, user_id, user_first_name, user_last_name, time) VALUES (?,?,?,?,?,?);",
postId, bucket, user.getId(), user.getFirstName(), user.getLastName(), System.currentTimeMillis());
}В INSERT запросе указываем полученный номер корзины, и все остальные поля, которые нам понадобится прочитать, когда мы захотим получить “лайки”.
И, наконец, метод для получения пользователей, лайкнувших публикацию:
public Iterator<User> getLikes(final UUID postId) {
Session session = CassandraDriver.getSession();
return new AbstractIterator<User>() {
private int currentBucket = 0;
private Iterator<Row> currentBucketRows = getBucketData(currentBucket);
@Override
protected User computeNext() {
if (currentBucket < MAX_BUCKETS) {
if (!currentBucketRows.hasNext()) {
currentBucketRows = getBucketData(++currentBucket);
}
if(currentBucketRows.hasNext()){
return userFromRow(currentBucketRows.next());
}
}
return endOfData();
}
private Iterator<Row> getBucketData(int bucket) {
ResultSet results = session.execute("SELECT * FROM likes_by_post_and_bucket WHERE post_id = ? AND bucket = ?;", postId, bucket);
return results.iterator();
}
};
}Этот метод возвращает итератор, так как потенциально пользователей может быть огромное количество, и если возвращать, например, список, то он может не поместится в память. Метод userFromRow просто конвертирует Row в сущность User.
Для того чтобв получить все лайки, нам необходимо запросить все корзины, и мы с помощью опять же Google Guava и её класса AbstractIterator последовательно переходим от одной корзины к другой. Это позволяет “лениво” опрашивать корзины, полезно, например, для постраничного вывода информации.
С другой стороны ничто не мешает запрашивать корзины асинхронно или параллельно несколькими потоками или машинами, что существенно ускорит процесс обработки всего объема данных.
Заключение
При создании модели данных может получится так, что для поддержки какого-то паттерна чтения может появиться партиция с очень большим количеством записей. В этом случае стоит обратиться к одной из техник бакетирования чтобы разложить все эти записи по разным корзинам, тем самым уменьшив размер партиций. Одним из способов бакетирования является применение согласованного хэширования. Это довольно простой и легко реализуемый способ, с фиксированным количеством корзин, зная максимальное количество корзин, можно всегда прочитать данные за определенное число запросов к базе, а также организовать параллельную обработку корзин.
Полезные ссылки
- Консистентное хэширование - небольшая статья на русском об основах согласованного хэширования
- Apache Cassandra. Первичные ключи и особенности хранения записей - собственно о ключах на русском.
- Sizing Cassandra Data - статья на английском о размерах данных в Apache Cassandra
- Basic Rules of Cassandra Data Modeling - базовые правила создания модели данных
- CassandraDataModeler - здесь я сделал картинки с моделью данных. А вообще этот инструмент помогает понять лучше понять модель данных.
- Guava HashingExplained - на английском о хэшировании в Google Guava
- Guava AbstractIterator - на английском об Итераторах в Google Guava