Метрики Apache Cassandra — часть 2: HintedHandOffManager
В этой статье пойдет речь о хинтах (hints) и о метриках, которые позволяют их отслеживать. По личному опыту скажу, что понимание и отслеживание данных метрик помогло на одном из проектов решить проблему с рассинхронизацией данных между репликами.
Неконсистентность
Для начала кратко расскажу о проблеме. Есть некоторая распределенная система использующая Apache Cassandra в качестве хранилища, где Replication Factor = 2 и все запросы к базе выполняются с Consistency Level = ONE. С течением времени, нагрузки и количество узлов системы росли. Но так сложилось, что никакой полноценной системы мониторинга не было, пока не появились большие проблемы с правильностью данных показываемых пользователю. Пользователь мог увидеть данные, которые уже как несколько дней или даже недель были неактуальны… а мог увидеть и актуальные результаты, как повезет. Так как не было мониторинга было трудно понять что происходит. Первая идея была, что это все “eventual consistency”, но почему eventual равен нескольким дням или неделям, когда все твердят о миллисекундах?
Ответ был обнаружен с помощью jConsole приконекченной к продакшен узлам кассандры. Ответом дал HintedHandOffManager.
HintedHandOffManager
Hints - это информация об операциях изменения данных, которые не были выполнены из-за недоступности узлов, на которых должны были быть произведены эти изменения. При запросе на изменение данных координирующий узел определяет на каких узлах должны быть произведены изменения, и, если какой либо из целевых узлов недоступен, координатор сохраняет у себя информацию о том, на каких узлах и какие данные должны быть изменены, чтоб при восстановлении доступности этих узлов повторить эту операцию. Данный механизм называется HintedHandOffManager и это один из механизмов отвечающих за синхронизацию данных между нодами, на ряду с Repair и ReadRepair.
HintedHandOffManager включен по умолчанию, и настраивается через cassandra.yaml, в котором есть один интересный параметр max_hint_window_in_ms - это время, за которое координатор будет сохранять хинты. Если узел недоступен более указанного времени то хинты не сохраняются для этого узла, по умолчанию max_hint_window_in_ms равен 3 часам.
Пример
Имеем кластер из трех узлов, с Replication Factor = 3 . И таблицей user:
CREATE TABLE nocqlru.user (
name text PRIMARY KEY,
billing boolean
)Пока все узлы друг для друга доступны, то все хорошо, добавим пользователя:
INSERT INTO user (name, billing) VALUES ('Vasya', false);И после добавления мы видим наши актуальные данные:
name | billing
-------+---------
Vasya | FalseС помощью JConsole подключимся ко всем нашим нодам и взглянем на параметр org.apache.cassandra.metrics:type=Storage,name=TotalHints, там есть единственный атрибут Count=0, он говорит о том, что все данные с этого узла ушли на нужные реплики.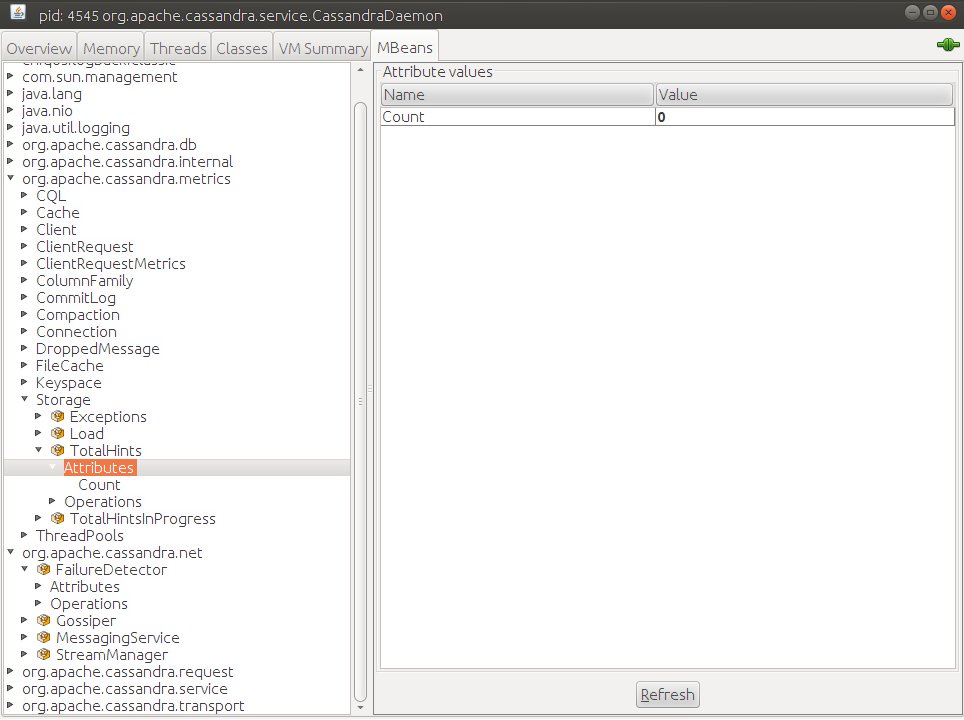
Кроме того в кейспейсе System есть таблица hints:
CREATE TABLE system.hints (
target_id uuid,
hint_id timeuuid,
message_version int,
mutation blob,
PRIMARY KEY (target_id, hint_id, message_version)
)В этой таблице собственно и сохраняется хинт: где изменить (поле target_id) и что и как изменить (поле mutation).
Hints_created
Теперь выключим две ноды из трех и попробуем обновить информацию о пользователе Vasya, выполним запрос с Consistency Level = ONE:
INSERT INTO user (name, billing) VALUES ('Vasya', true);Запрос выполнится успешно и мы сможем получить актуальны данные выполнив SELECT:
name | billing
-------+---------
Vasya | TrueНо при этом координатор сохранит у себя информацию о том, что в будущем нужно будет повторить операцию записи на узлы которые были недоступны, посмотрим на метрику org.apache.cassandra.metrics:type=Storage,name=TotalHints, теперь мы видим Count=2
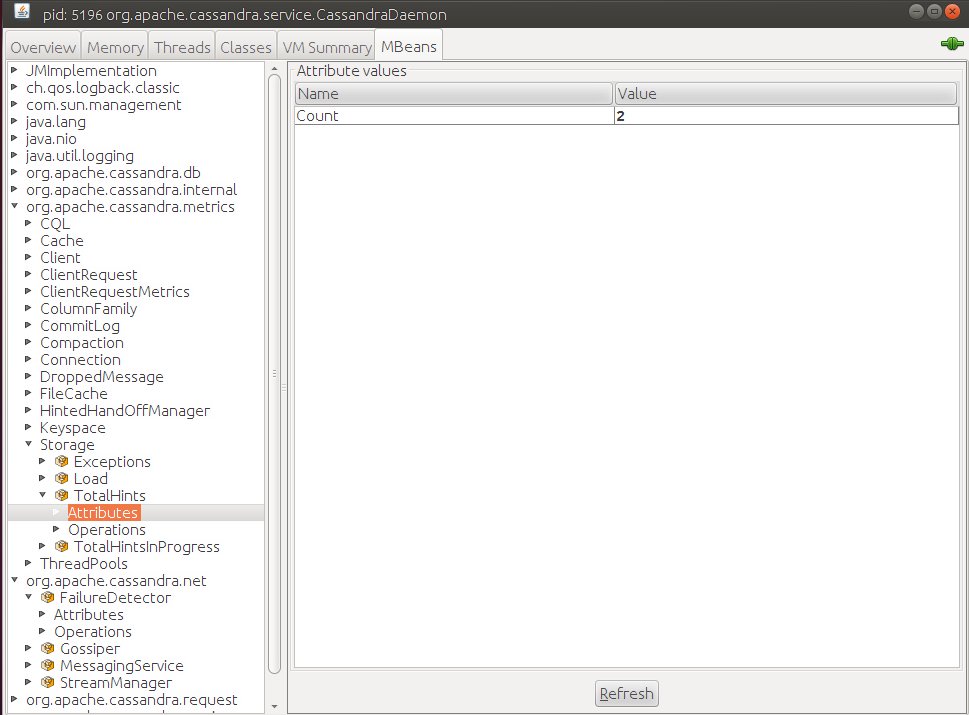
Более того, теперь появились еще две метрики: org.apache.cassandra.metrics:type=HintedHandOffManager,name=Hints_created-127.0.0.2 org.apache.cassandra.metrics:type=HintedHandOffManager,name=Hints_created-127.0.0.3
Они показывают количество хинтов для конкретных узлов: 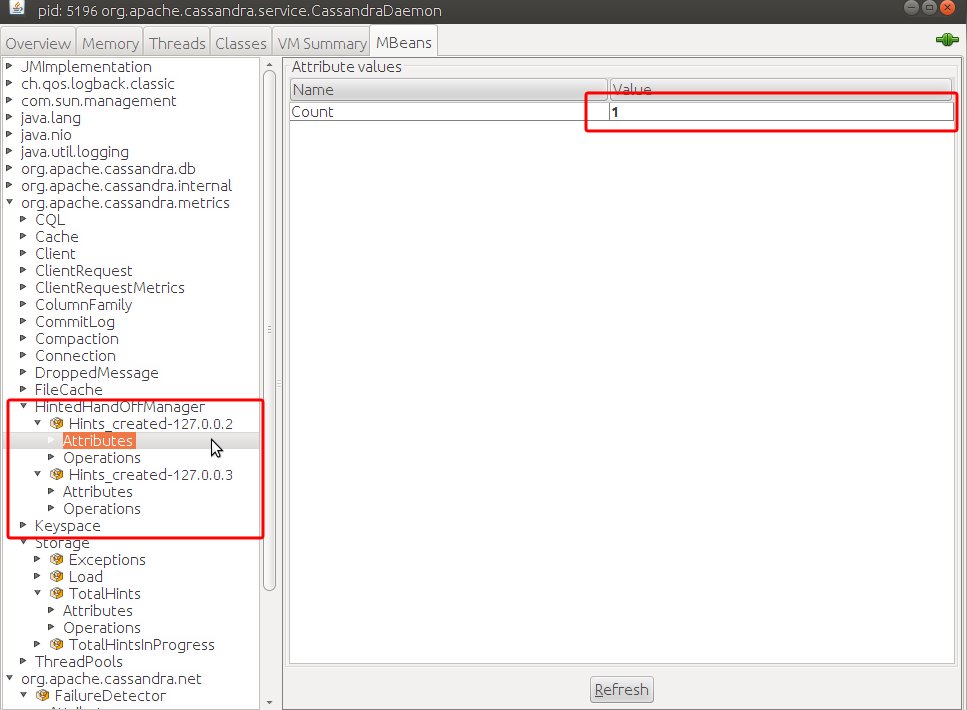
Теперь обратимся к таблице hints и увидим там сами хинты:
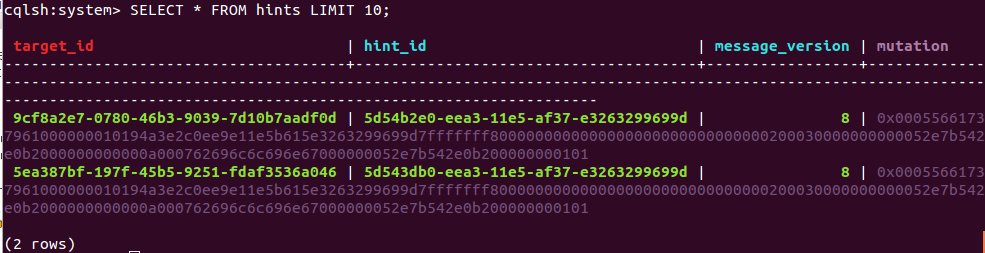
Если с тех пор как ноды стали недоступны прошло меньше времени, чем указано в параметре max_hint_window_in_ms, и мы восстановили доступность узлов друг для друга, то операции сохраненные в таблице hints будут выполнены вновь автоматически, данные между нодами синхронизируются и пользователь будет видеть актуальный результат.
Hints_not_stored
Но если момент недоступности узлов остался для нас незамеченным, и ноды не видят друг друга длительный промежуток времени, то Cassandra перестает сохранять хинты для таких нод, в этом случае можно наблюдать метрики с названием Hints_not_stored.
Представим, что прошло времени больше чем указано в max_hint_window_in_ms и мы добавляем иноформацию о пользователе Petya:
INSERT INTO user (name, billing) VALUES ('Petya', false);Запрос будет выполнен успешно, и мы все также сможем получить актуальные данные выполнив SELECT:
cqlsh:nocqlru> SELECT * FROM user WHERE name='Petya';
name | billing
-------+---------
Petya | False
(1 rows)Вроде бы ничего плохого? Но интересное начнется когда мы восстановим доступность узлов, а сейчас можем взглянуть в JConsole и увидим, что для двух узлов хинты не были сохранены: org.apache.cassandra.metrics:type=HintedHandOffManager,name=Hints_not_stored-127.0.0.2 и org.apache.cassandra.metrics:type=HintedHandOffManager,name=Hints_not_stored-127.0.0.3
В этом случае никаких новых записей в таблице hints не будет, и, даже когда будет восстановлена доступность узлов, данные не будут синхронизированы автоматически. Что в итоге приведет к тому что один и тот же SELECT запрос с Consistency Level = ONE будет возвращать разные данные, в зависимости от того какая реплика вернет результат быстрее:
cqlsh:nocqlru> SELECT * FROM user WHERE name='Petya';
name | billing
------+---------
(0 rows)или
cqlsh:nocqlru> SELECT * FROM user WHERE name='Petya';
name | billing
-------+---------
Petya | False
(1 rows)Для того чтоб избежать такого поведения необходимо выполнить операцию ручной синхронизации с помощью nodetool repair, которая синхронизирует данные между узлами. Более того repair рекомендуется проводить регулярно.
Заключение
Возвращаясь к проблеме обозначенной в начале статьи можно сделать вывод о том, что наличие системы мониторинга и понимания метрик Кассадры очень важная вещь для обеспечения стабильной работы системы и при поиске “магии” происходящей с данными. Иначе довольно трудно следить за состоянием большого кластера и узнать о недоступности узлов можно спустя только несколько дней, получив гору жалоб от пользователей а потом еще потратить огромное время на исследование проблемы, которой вообще могло бы не быть.
Полезные ссылки
- About hinted handoff writes - Подробное описание механизма HintedHandOff на английском.
- Nodetool repair - Описание команды repair